uCalc LMNL examples
Example 1: Adding LMNL code to a plain text poem
Example 2: Transforming LMNL to HTML
Introduction
XSLT targets a very specific kind of code, whereas uCalc is designed to parse XML just as easily as high-level programming language source code, or text of any other kind. If one can coherently describe how a given text should be parsed, then uCalc can parse it (hmm, maybe a slogan might be: If you can describe it, uCalc can parse it). uCalc has no preference for any given kind of syntax or construct, so overlapped tagging and marked up annotation is not a hurdle.
I eventually plan to write documentation on how uCalc parses, but for now, in the context of recursive LMNL syntax, uCalc goes through the text and matches text based on patterns you define. When a pattern is found, and the match is modified, the parser moves on if the Pass once property for the pattern is set to True, otherwise it reparses the newly modified text in search of new matches. This process can go on indefinitely until no new matches are found, or until the Max quota for the pattern is reached (if the Max property is set to a value other than -1). In addition to allowing multiple passes for each pattern, you can also group patterns into pass groups, as you’ll see in the examples.
To play with these examples:
· Download the current beta from: www.ucalc.com/beta/ucsearch15.zip
· Visit: http://www.ucalc.com/lmnl/ and download *.uc and *.txt (NOTE: Internet Explorer apparently renames .uc files as .txt; make sure to rename files back to their original names after downloading)
· Most .uc files should go in the /Misc directory, except for txt.uc, which should go in the /FileTypes directory
Example 1: Adding LMNL code to a plain text poem
Before I was given a specific challenge, I started trying to understand LMNL a little bit by visiting this link, which was given to me:
http://balisage.net/Proceeding
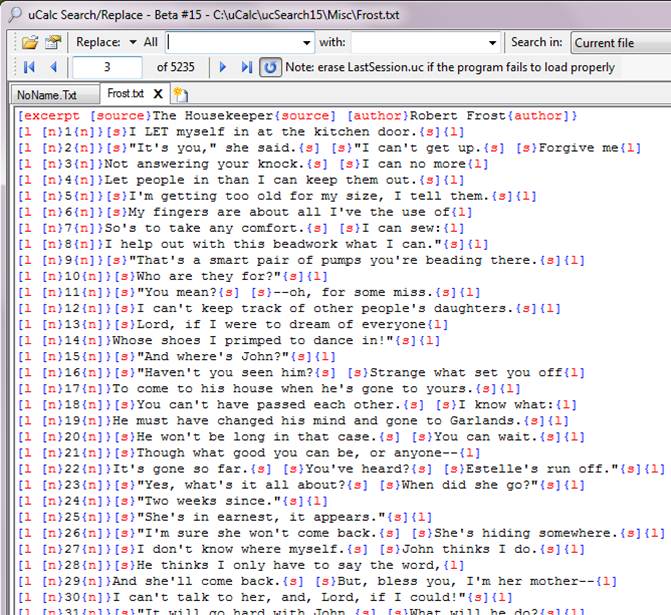
It gave a few lines of a Robert Frost poem encoded in LMNL. To better understand the process, I Googled the full text of the poem, and created a simple transformation file to add LMNL encoding to it.
The original text is here: http://www.ucalc.com/lmnl/Frost.txt
The transformed result looks like this:
If you just want to quickly get to this view, then right-click the Frost.uc file like this:
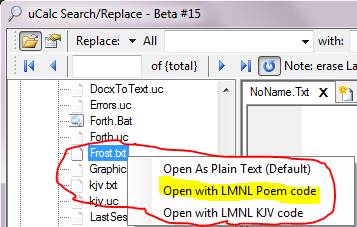
The code that allows you to open your files in this way is at:
http://www.ucalc.com/lmnl/txt.uc
Note: When you open the file by right-clicking, you’ll notice that the color is a bit off (in beta #15). I am aware of this bug. Until it’s fixed, If you want it to look just like the picture box above, then open the file as plain text, and then open the transformation files and apply them that way instead.
You’ll notice that txt.uc (which should be placed in the /FileTypes directory) includes references to these two transformation files:
http://www.ucalc.com/lmnl/PoemToLMNL.uc
http://www.ucalc.com/lmnl/PrettyLMNL.uc
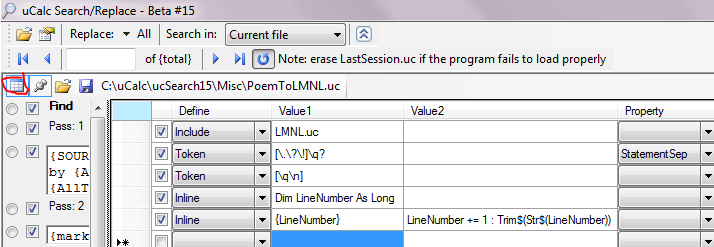
These are plain text files, but are best viewed by loading them in uCalc. The explanation for PrettyLMNL.uc is similar to the one for XML formatting at: http://www.ucalc.com/beta/#XMLColor . If you right-click PoemToLMNL.uc from within uCalc and choose Open as Transformation, it should look like this:
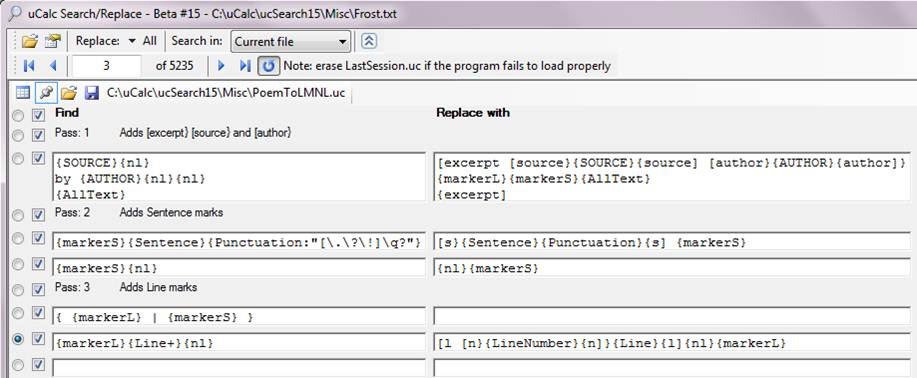
Notice how it takes 3 separate passes to accomplish the task.
Note that the use of multiple lines in the Find column has a different effect than in the Replace column. The same goes with whitespace (for the most part). In the Find column, whitespace and NewLines do not affect the transformation; you can break things down into multiple lines (as I’ve done with the first pattern) simply to make it easier to read. In the Replace with column, however, NewLine and whitespace are part of the literal output (there are exceptions; but I won’t get into that unless asked).
Also note that in the Find section, curly braces have special meaning, whereas in the Replace section curly braces have meaning only for corresponding pattern variables from the Find section. So {SOURCE} in the Replace section represents text that was matched in the first line, whereas {source] represents literal text.
{SOURCE} grabs all text (one token at a time) starting from the beginning, until it reaches a new line, indicated by {nl}. {nl} is defined in LMNL.uc as holding the NewLine character, whereas {SOURCE} is defined here as a general pattern variable. {AllText} was defined in LMNL.uc with a regular expression pattern that matches all characters. It will match everything that comes after the {AUTHOR} line.
In Pass #2, you have two patterns that start the same way. Whenever you have multiple patterns that start the same way, uCalc tries to match that last definition (in this case {markerS}{nl}) first. If that doesn’t match, it tries the next one up the list, until it either finds a match, or none are found, in which case it moves on to the next token.
In Pass #3, the + sign in {Line+} causes the pattern to cross statement separator boundaries, such as !, ., and ?. This probably answers the question about LMNL range. The first pattern in Pass #3, causes {markerL} and {markerS} to disappear (by being replaced with a blank), once they reach the end of the text ({markerS} will already reach the bottom by the end of Pass #2).
Each search item has its own configurable properties. By default the Pass once property is set to True. In this particular case, it was necessary to set this property to False for most patterns.
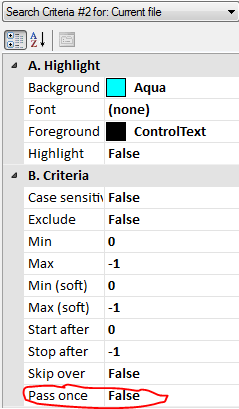
Also by default Highlight is set to True. Here I’ve set it to False. When building a solution, it is often useful to use highlighting. Also, you may want to start by check-marking only the patterns in Pass #1. Once everything’s in order there, you can checkmark the items in the next pass. There’s a useful column (not shown here) that displays the number of matches per pattern. If a pattern is getting 0 matches, this could indicate that it needs to be tweaked.
In order to add a group pass, change the above property in a blank pattern to a value other than 0. This will change the item’s appearance. Also notice the Comment property. For passes, the comment appears next to the pass. For other items, the comment appears as a tool tip.

If you click on the upper-left icon that’s circled in red, you should see the setup section, which is also important and looks like this:
I tend to stuff messy definitions in this section, and the more straightforward-looking parts in the Find/Replace section.
Notice that the setup starts by loading the contents of http://www.ucalc.com/lmnl/LMNL.uc . That file is somewhat of a modification of XML_Defs.uc . Here I’ve defined tokens that might be useful in LMNL such as alphanumeric and whitespace (I found it more convenient not to make the NewLine character whitespace the way I did in XML_Defs). Also of note, I’ve defined {markerL} for line marker, and {markerS} for sentence marker (they are arbitrarily mapped to non-text characters, but I plan to change it so that markers aren’t associated with any character code). There’s some extra code in there I thought of using but eventually didn’t. You can further modify this file as needed.
After including LMNL.uc, the next line defines the period, question mark, and exclamation mark as statement separators (using a regular expression pattern) in this context. What that means is that when trying to find a pattern match, it stops at the separator (unless you explicitly force the pattern argument to cross beyond the separator as we’ve done with {Line+}). It’s kind of like the semi-colon in C, or the NewLine in BASIC.
The next line changes the quote mark and new line characters into ordinary tokens with no properties, otherwise items within quotes would be treated in a special way (this line should probably be placed in LMNL.uc).
The line after that allocates a variable named LineNumber using the programming language (BASIC.uc) specified in LMNL.uc. Every time {LineNumber} occurs in a transformation, the variable is incremented, and its value is inserted at the given location in the replacement.
Example 2: Transforming LMNL to HTML
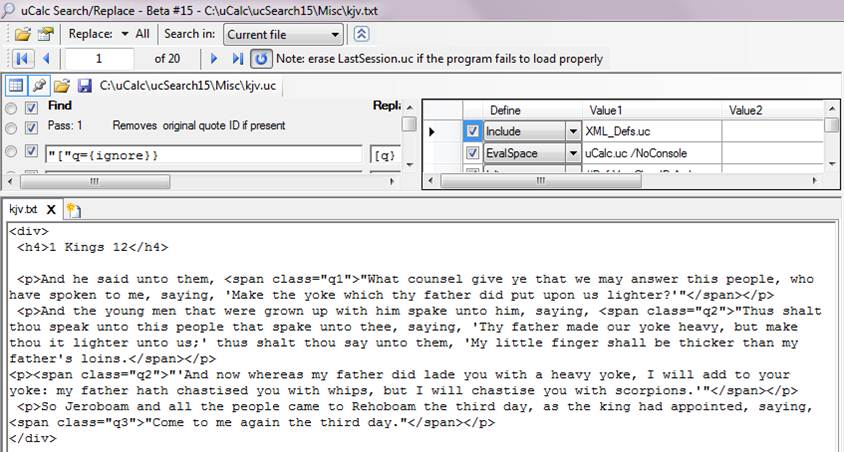
You may right-click the KJV.Txt sample file and choose Open with KJV LMNL code if you want to immediately see the output based on the specs that were given. But if you want to look under the hood, load it up as plain text. Then right-click KJV.uc and open it as a transformation file. It should look something like this (I’ve also opened up the definition area on the right, which isn’t opened by default):

The definition table on the far right should look familiar if you started with Example #1. I used XML_Defs.uc instead of LMNL.uc because of certain properties that lend themselves to HTML (you can eventually revise LMNL.uc to have it take care of everything), such as < and > as statement separators.
The attribute in tags like [q=i} didn’t seem to contribute to the solution, so in Pass #1, I simply strip out that part. uCalc interprets square brackets and curly braces in special ways, whereas LMNL uses them as well. By enclosing those characters in quotes, this prevents uCalc from trying to interpret them. A closing curly brace or square bracket is not interpreted by uCalc, unless it has a matching opening brace or bracket. Therefore it wasn’t necessary to place those in quotes.
In Pass #2, I have it turn the outer quote into a different tag than inner quotes. It’s very important to note that for that one, the Pass once property is set to true. This means that when a quoted pattern is matched, it won’t recursively find matches within the quotes. That’s how the outer quotes are distinguished. Any [q} tags enclosed within outer quotes are left unparsed in this pass.
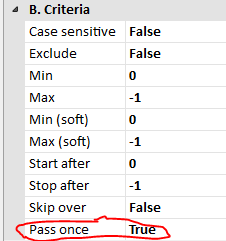
Pass #3 should hopefully look very straightforward based on other explanations so far. As mentioned earlier, the spacing and multiple lines in the Find column, such as in Pass #3, simply make it easier to read the pattern (they could have all been jammed into one long line), whereas the placement of characters in the Replace with column is literal. uCalc will first find the [excerpt} block of text. For this one the Pass once property is set to False. So, once that block of text is modified to <div> . . . </div>, it is parsed again. This time it will find the [verse} sections.
It’s probably possible to reduce the number of overall passes here. In fact, typically there might often be several ways of doing things. You might come up with a solution that doesn’t even look like this one. Anyway, I found it convenient to have a separate pass that handles the inner quotes. The two patterns in Pass #4 start the same way, so the last one is tried first. If a [q} finds a matching {q] without crossing any statement separators (< and > are defined as such in XML_Defs.uc), then the match is transformed to '{QUOTE}' (where {QUOTE} represents the match found between [q} and {q]). If not, then it tries to match [q}{QUOTE} </p> <p> and transforms it accordingly.
Pass #5 is similar to Pass #4, except you have the ID value that’s incremented or decremented with {ID+} or {ID-}; the {ID} value is inserted in the class attribute. You’ll see the definition for those in the definition section.
Pass #6 was added in order to display an error message for any stray LMNL code that’s left in the output after the other passes.
The final output (with word wrap turned on, and line-numbering off) looks like this: